
学生姓名:伍凯
班班级级:工业2019-01班
指导教师:何丽娜
毕设题目:基于数据驱动FMEA的供应链风险分析


一、概况
1.选题意义
本文采用数据驱动的失效模式与影响分析(FMEA)方法对智能网联汽车供应链中可能出现的风险因素进行风险评估和分析研究工作,具体意义在于:不同于以往仅定性分析供应链的风险,本文采用定性—定量相结合的方法。对某智能网联汽车企业进行整体分析,识别各部门、各区域存在的风险因素,建立风险参数-风险因素的全方位诊断数据库,进一步进行智能网联汽车企业供应链的风险评估,有助于企业提前识别风险并采取有效措施,减少供应紧缺、中断等问题的发生。
第一,供应链的良性管理对于一个智能网联汽车企业而言是相当重要的,其产品、技术的复杂性决定了其供应链的高风险性。在识别了供应链可能的风险来源和风险因素后,有助于管理者从管理、设计方面改善供应链,提前识别风险因素或者加强对薄弱环节的控制,减少供应链中断的发生,提高企业的核心竞争力。
第二,在制造业中,传统的FMEA方法,直接采用数字对零部件的失效模式进行评定打分的过程并不适用于现如今智能网联汽车企业供应链的风险管理。(1)供应链趋于复杂化,相关工作人员由于缺乏对整体的把握,采用数字打分并不一定切合实际情况;(2)对于涉及供应链的有关不同部门的专家所希望采取的方法不一。因此,需要采用一种可以统一各种不同信息的评价方法获取工人和专家的信息更符合实际情况。
第三,传统的FMEA方法中对于失效模式或风险因素的严重性(S)、发生率(O)和检测率(D)的计算都是基于专家评定的,从提高供应链风险评估的可靠性的角度来看,可以使用新的数据驱动分析方法来根据数据选择发生率(O)的值,这将有助于使FMEA的结果更加可靠,减少对个人及其主观评估的依赖。
2.任务分解
本文以某智能网联汽车企业供应链的风险因素为研究对象,对供应链风险管理过程中各部门、各环节可能出现的风险因素进行识别和评估,基于信息融合和数据驱动的失效模式与影响分析(Data-driven Failure Mode and Effects Analysis,Data-driven FMEA)方法实现区间风险优先级数(Interval Risk Priority Numbers,IRPNs)的计算与比较,从而对供应链运作过程中各区域、各环节的潜在风险因素进行预防,并根据其优先级采取相应的措施。具体目标分解如下:
(1)供应链风险管理和FMEA方法的国内外研究现状分析;
(2)分析供应链风险的关键因素,建立风险因素的标准集合,然后对以上各风险因素的两个风险因子S和D构建它们的原始风险因素信息评价(Risk Factor Information Evaluation, RFIE)矩阵;
(3)基于信息融合的理论建立考虑异构性评价信息的FMEA方法的应用模型,明确区间评价值严重性S和检测率D的计算流程;
(4)建立风险参数-风险因素的全方位诊断数据库,并设计基于数据驱动FMEA方法的发生率O预测模型,最后实现区间风险优先级数的计算和比较,以达到供应链风险评估的目的;
(5)针对某智能网联汽车企业的供应链风险识别和评估问题进行案例研究,验证所提出方法的有效性和可靠性。
二、已完成工作
1.已构建基于信息融合和数据驱动FMEA的供应链风险评估模型,能够将异构评价信息整合转化为S、D的区间值,并基于风险数据集预测发生率O。
(1)基于信息融合变换评价信息矩阵得到S、D的区间值
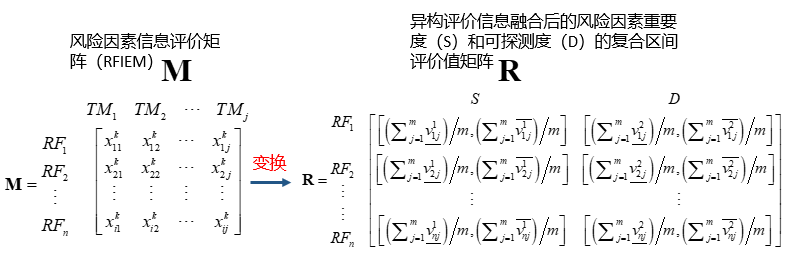
其中包含单一数字评分和区间数字评分的转化,转化步骤如下图。


图1 单一评分转化过程 图2 区间评分转化过程
(2)基于数据驱动FMEA预测风险发生率O
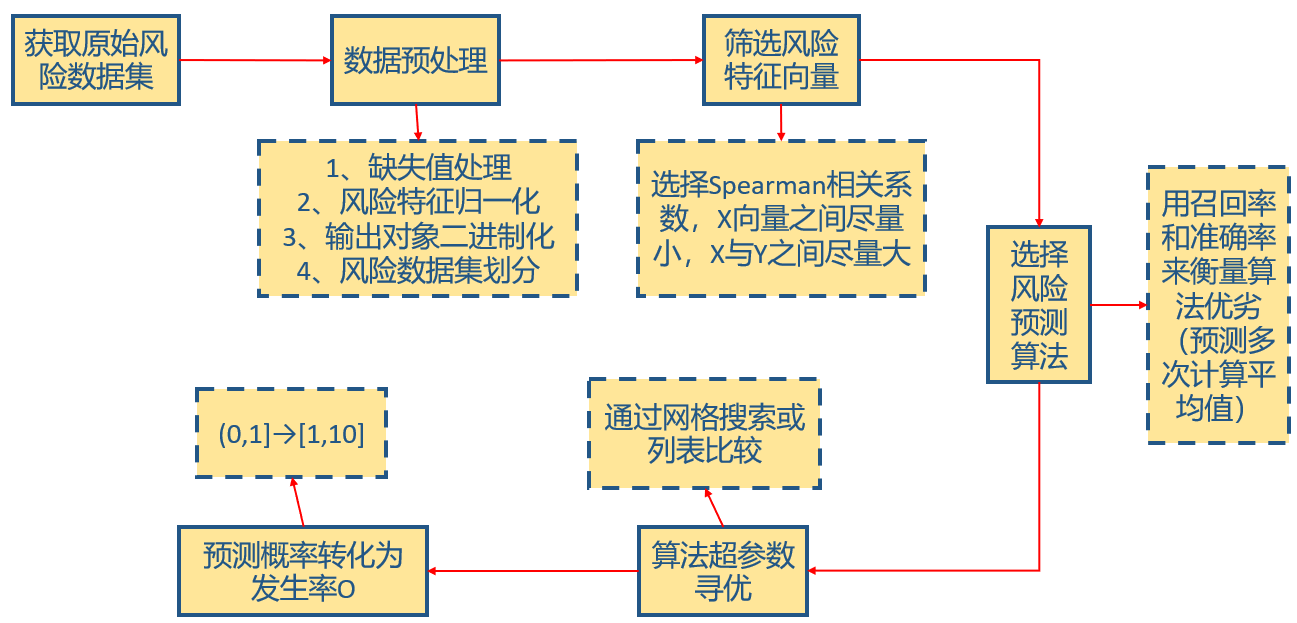
图3 风险发生率预测流程
(3)基于区间风险因素优先度排序进行风险评估

图4 IRPNs计算过程和结果矩阵
2.以某智能网联汽车企业为例,将风险评估模型进行应用,目前已将S、D的区间评价值和O预测得到。
(1)求取S、D区间评价值
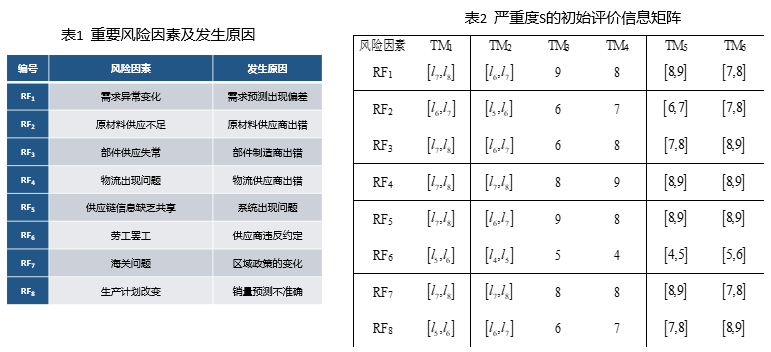
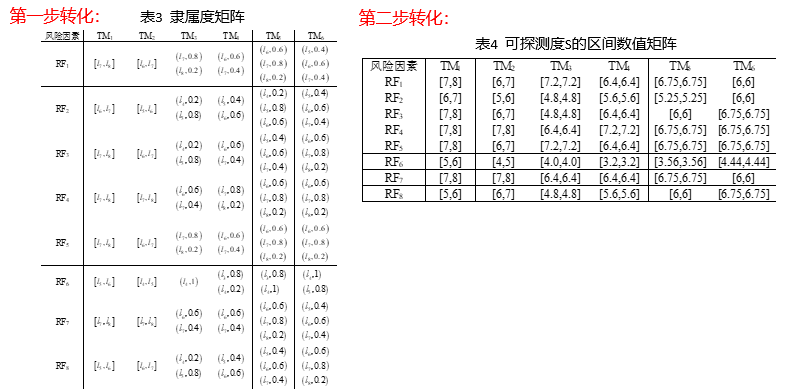
(2)预测确定风险发生率
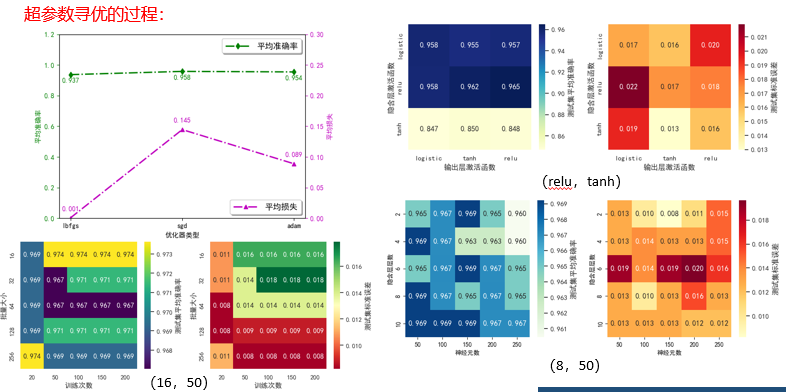
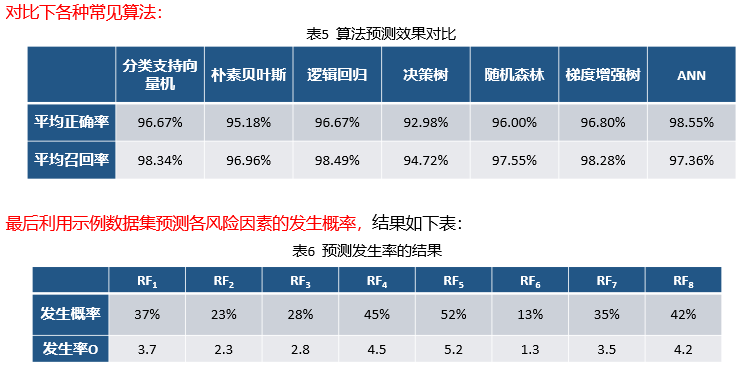
三、下一步工作计划
(1)完成所有风险因素的区间风险优先级数的计算,并基于区间比较理论进行排序,从而完成风险评估。
(2)对风险评估结果进行分析,并和传统的FMEA方法进行比较。
(3)完善论文写作,注意结构安排和章节标题,润色文字和图片,并及时和指导老师审核阶段性成果。

问题一:初始的信息评价矩阵是如何转化为S、D的区间值矩阵的?
回答:谢谢老师的提问!初始的风险因素信息评价矩阵包含有语言评价和数字评价,通过将风险因素信息评价矩阵的原始元素表达在九粒度语言模糊集上,求出对应的隶属度,再将该模糊集逆模糊化,将序列对形式的隶属度转化为清晰的严重度S和可探测度D的区间评价数值。
问题二:风险预测MLP模型的超参数寻优需要进行几次?
回答:谢谢老师的提问!我们要对每一个风险因素的风险数据集对应的MLP预测模型进行一次超参数寻优,得到该风险因素的MLP参数组,这样对示例数据集来说就可以用每个MLP模型去预测对应风险因素的发生率O了。

对我而言,通过这次中期汇报又重新梳理了一遍风险评估模型的建模过程,并在可视化的展示过程中找到了自己存在的一些问题和疏忽的地方,这是在撰写论文时不曾注意到的。同时老师们提出的问题让我明确了改进的方向,后续安排中会优先处理,也加强了我的紧迫感,要适当加快论文初稿的撰写进度。通过毕设的学习与应用,巩固了python的使用,也更熟悉了超参数寻优的流程。
感谢何丽娜老师的指导和督促,尤其在获取风险数据这个问题上给了我一个很好的解决思路,也教会了我很多论文写作技巧。

